在大型电商平台中,一个商品同时归属于多个分类是常见的业务场景。例如,一款智能手机可能同时出现在“手机通讯”、“数码配件”甚至“礼品推荐”等多个分类目录下。这种一对多的映射关系,在数据量达到亿级规模时,对商品详情页的架构设计提出了严峻挑战。本文将深入解密支撑亿级商品详情页的技术服务架构,其核心演进路径正是围绕高效、灵活地处理“商品-多分类”这一关系而展开。
第一阶段:集中式数据库与直接关联
早期架构通常采用集中式关系型数据库(如MySQL)存储商品与分类的关联关系,通过建立“商品-分类”关联表来实现。当用户访问某个分类时,系统通过SQL联表查询快速获取该分类下的商品ID列表,再根据ID查询商品详情。这种方案的优点是逻辑简单、数据强一致。但随着商品与分类数据量的爆炸式增长,尤其是在促销期间的高并发访问下,数据库的联表查询和I/O压力成为瓶颈,页面响应延迟明显增加,难以支撑亿级数据的实时高效访问。
第二阶段:引入缓存与读写分离
为缓解数据库压力,架构演进中引入了多级缓存策略。使用Redis等内存数据库缓存热门分类下的商品ID列表以及商品详情数据。当商品分类信息更新时(如商品上架到新分类),系统会异步更新缓存。数据库层面实施读写分离,将读请求导向从库。这一阶段显著提升了读取性能。它未能根本解决“商品-多分类”带来的复杂性:一个商品信息的变更(如价格、库存)需要失效或更新所有关联分类下的缓存片段,维护一致性成本高昂,缓存命中率在长尾分类下不理想,且系统扩展性依然受限。
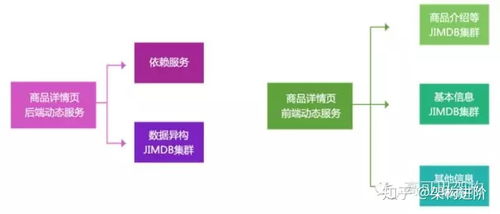
第三阶段:数据异构化与原子服务
这是架构演进的关键转折点。核心思想是将“商品详情页”本身作为一个独立的数据聚合体进行构建和存储,而非每次动态拼装。具体措施包括:
- 数据异构化:构建独立的“商品详情”数据存储(如使用HBase、OceanBase或ES),其每条记录就是一个完整的、渲染好的商品详情数据模型。当后台更新商品基础信息或分类关系时,通过消息队列(如Kafka)触发一个异步的“详情页构建引擎”。该引擎会拉取所有相关的商品、分类、营销数据,并生成一个新的、包含了所有适用分类上下文(如分类名称、面包屑导航)的详情页数据快照,写入异构存储。这意味着,一个商品有N个分类,理论上就可能生成N个不同侧重点的数据快照(实践中会进行合并优化)。
- 原子服务拆分:将分类服务、商品基础服务、库存服务、价格服务等拆分为独立的微服务。详情页构建引擎通过调用这些原子服务获取数据。服务之间解耦,独立伸缩。
- 智能路由与静态化加速:用户请求到达时,接入层根据URL中的分类ID,直接路由到异构存储中对应的、已预先构建好的详情页数据,实现近乎静态页面的访问速度。多级缓存(CDN、本地缓存)用于存储最终渲染的HTML或JSON数据。
第四阶段:平台化与弹性伸缩
在第三阶段基础上,架构进一步演变为一个技术服务平台,其特征是:
- 实时与最终一致性结合:对于价格、库存等强实时性数据,采用“异步构建快照+实时服务接口兜底”的方式。即详情页展示快照中的库存,但下单前调用实时库存服务进行最终校验。
- 智能化数据处理:利用大数据平台分析商品与分类的访问模式,智能预热缓存,优化详情页数据构建的优先级和粒度。
- 弹性伸缩与容灾:所有服务无状态化,可基于容器化技术(如Kubernetes)快速弹性伸缩。存储层多地域部署,实现异地多活,保障高可用性。
- 统一网关与服务治理:通过API网关统一接入,提供服务发现、流量控制、熔断降级等治理能力,确保“商品-多分类”这一复杂调用链路的稳定性。
技术
从直接依赖关系型数据库联表,到通过数据异构化将“商品-多分类”的复杂性在写入时消化,生成可直接读取的聚合数据,是亿级商品详情页架构演进的核心理念。这种架构将计算密集型的数据组装过程从实时查询路径中剥离,以空间(存储多份聚合数据)和最终一致性换取了极致的读取性能和系统扩展能力,从而能够稳健地支撑海量商品、复杂分类关系下的高并发访问,为业务提供了强大的技术服务底座。